Open an interactive version of this example on Binder:
![]()
Maximal Policies#
This example demonstrates the stochastic reachability algorithm to compute the maximal policy in the terminal (first) sense.
By default, the system is a double integrator (2D stochastic chain of integrators).
To run the example, use the following command:
python examples/reach/stoch_reach_maximal.py
[1]:
import gym
import numpy as np
from functools import partial
from gym.envs.registration import make
from gym_socks.kernel.metrics import rbf_kernel
from gym_socks.algorithms.reach.kernel_sr_max import kernel_sr_max
from gym_socks.sampling import transition_sampler
from gym_socks.sampling import grid_sampler
from gym_socks.utils.grid import boxgrid
from gym_socks.utils.grid import cartesian
/home/docs/checkouts/readthedocs.org/user_builds/socks/envs/develop/lib/python3.9/site-packages/tqdm/auto.py:22: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Configuration variables.
[2]:
system_id = "2DIntegratorEnv-v0"
time_horizon = 5
sigma = 0.1
regularization_param = 1
Generate The Sample#
We demonstrate the algorithm on a simple 2-D integrator system, and sample on a grid within the region of interest. Note that this is a simplification in order to make the result look more “uniform”, but is not specifically required for the algorithm to work.
[3]:
env = make(system_id)
sample_size = 3125 # This number is chosen based on the values below.
state_sample_space = gym.spaces.Box(
low=-1.1, high=1.1, shape=env.state_space.shape, dtype=env.state_space.dtype
)
state_sampler = grid_sampler(boxgrid(space=state_sample_space, resolution=25)).repeat(5)
action_sampler = grid_sampler(cartesian(np.linspace(-1, 1, 5)))
S = transition_sampler(env, state_sampler, action_sampler).sample(size=sample_size)
# Generate a set of admissible control actions.
A = cartesian(np.linspace(-1, 1, 5))
/home/docs/checkouts/readthedocs.org/user_builds/socks/envs/develop/lib/python3.9/site-packages/gym/utils/env_checker.py:144: UserWarning: WARN: Agent's minimum observation space value is -infinity. This is probably too low.
logger.warn(
/home/docs/checkouts/readthedocs.org/user_builds/socks/envs/develop/lib/python3.9/site-packages/gym/utils/env_checker.py:148: UserWarning: WARN: Agent's maxmimum observation space value is infinity. This is probably too high
logger.warn(
/home/docs/checkouts/readthedocs.org/user_builds/socks/envs/develop/lib/python3.9/site-packages/gym/utils/env_checker.py:172: UserWarning: WARN: Agent's minimum action space value is -infinity. This is probably too low.
logger.warn(
/home/docs/checkouts/readthedocs.org/user_builds/socks/envs/develop/lib/python3.9/site-packages/gym/utils/env_checker.py:176: UserWarning: WARN: Agent's maximum action space value is infinity. This is probably too high
logger.warn(
/home/docs/checkouts/readthedocs.org/user_builds/socks/envs/develop/lib/python3.9/site-packages/gym/utils/env_checker.py:200: UserWarning: WARN: We recommend you to use a symmetric and normalized Box action space (range=[-1, 1]) cf https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html
logger.warn(
/home/docs/checkouts/readthedocs.org/user_builds/socks/envs/develop/lib/python3.9/site-packages/gym/envs/registration.py:619: UserWarning: WARN: Env check failed with the following message: array([nan], dtype=float32) (<class 'numpy.ndarray'>) invalid
You can set `disable_env_checker=True` to disable this check.
logger.warn(
We define the target tube and the constraint (safety) tube, which are sequences of bounded sets indexed by time. Here, we define the target tube such that it is between -0.5 and 0.5, and specify the constraint tube to be between -1 and 1.
[4]:
target_tube = [
gym.spaces.Box(low=-0.5, high=0.5, shape=(2,), dtype=np.float32)
] * time_horizon
constraint_tube = [
gym.spaces.Box(low=-1, high=1, shape=(2,), dtype=np.float32)
] * time_horizon
# Generate test points.
x1 = np.linspace(-1, 1, 50)
x2 = np.linspace(-1, 1, 50)
T = cartesian(x1, x2)
Algorithm#
We then run the algorithm to compute the safety probabilities at each of the test points for the first-hitting time stochastic reachability problem. We can easily change to the terminal-hitting time problem by changing “FHT” below to “THT”.
[5]:
safety_probabilities = kernel_sr_max(
S=S,
A=A,
T=T,
time_horizon=time_horizon,
constraint_tube=constraint_tube,
target_tube=target_tube,
problem="FHT",
regularization_param=regularization_param,
kernel_fn=partial(rbf_kernel, sigma=sigma),
verbose=False,
)
Results#
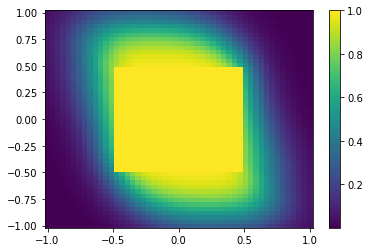
We then plot the results for all of the test points. The warmer colors indicate higher safety probabilities.
[6]:
import matplotlib
import matplotlib.pyplot as plt
# Reshape data.
XX, YY = np.meshgrid(x1, x2, indexing="ij")
Z = safety_probabilities[0].reshape(XX.shape)
# Plot flat color map.
fig = plt.figure()
ax = plt.axes()
plt.pcolor(XX, YY, Z, cmap="viridis", shading="auto")
plt.colorbar()
plt.show()