Open an interactive version of this example on Binder:
![]()
Satellite Rendezvous and Docking#
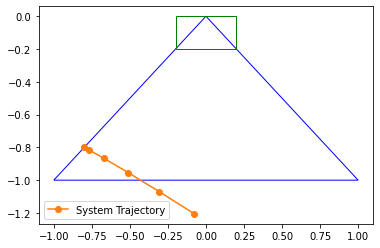
Constrained stochastic optimal control problem using CWH dynamics. Note that the solution is currently unstable. This is partly due to the fact that the CWH dynamics are extremely sensitive to inputs, but also due to the fact that random sampling is not guaranteed to generate a sequence of control actions that will slow the spacecraft down. Thus, it generally fails to satisfy the terminal constraint.
To run the example, use the following command:
python examples/control/satellite_rendezvous.py
[1]:
import gym
import numpy as np
from gym.envs.registration import make
from gym_socks.algorithms.control.kernel_control_fwd import KernelControlFwd
from gym_socks.kernel.metrics import rbf_kernel
from gym_socks.sampling import space_sampler
from gym_socks.sampling import transition_sampler
from gym_socks.utils.grid import boxgrid
/home/docs/checkouts/readthedocs.org/user_builds/socks/envs/develop/lib/python3.9/site-packages/tqdm/auto.py:22: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Configuration variables.
[2]:
system_id = "CWH4DEnv-v0"
regularization_param = 1e-7
time_horizon = 5
# For controlling randomness.
seed = 123
Generate the Sample#
We generate a random sample from the system, and choose random control actions and random initial conditions.
[3]:
env = make(system_id)
env.seed(seed)
sample_size = 2500
state_sample_space = gym.spaces.Box(
low=np.array([-1.1, -1.1, -0.06, -0.06], dtype=np.float32),
high=np.array([1.1, 1.1, 0.06, 0.06], dtype=np.float32),
shape=(4,),
dtype=np.float32,
seed=seed,
)
action_sample_space = gym.spaces.Box(
low=-0.05,
high=0.05,
shape=(2,),
dtype=np.float32,
seed=seed,
)
state_sampler = space_sampler(state_sample_space)
action_sampler = space_sampler(action_sample_space)
S = transition_sampler(env, state_sampler, action_sampler).sample(size=sample_size)
A = boxgrid(space=action_sample_space, resolution=[20, 20])
/home/docs/checkouts/readthedocs.org/user_builds/socks/envs/develop/lib/python3.9/site-packages/gym/utils/env_checker.py:144: UserWarning: WARN: Agent's minimum observation space value is -infinity. This is probably too low.
logger.warn(
/home/docs/checkouts/readthedocs.org/user_builds/socks/envs/develop/lib/python3.9/site-packages/gym/utils/env_checker.py:148: UserWarning: WARN: Agent's maxmimum observation space value is infinity. This is probably too high
logger.warn(
/home/docs/checkouts/readthedocs.org/user_builds/socks/envs/develop/lib/python3.9/site-packages/gym/utils/env_checker.py:172: UserWarning: WARN: Agent's minimum action space value is -infinity. This is probably too low.
logger.warn(
/home/docs/checkouts/readthedocs.org/user_builds/socks/envs/develop/lib/python3.9/site-packages/gym/utils/env_checker.py:176: UserWarning: WARN: Agent's maximum action space value is infinity. This is probably too high
logger.warn(
/home/docs/checkouts/readthedocs.org/user_builds/socks/envs/develop/lib/python3.9/site-packages/gym/utils/env_checker.py:200: UserWarning: WARN: We recommend you to use a symmetric and normalized Box action space (range=[-1, 1]) cf https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html
logger.warn(
/home/docs/checkouts/readthedocs.org/user_builds/socks/envs/develop/lib/python3.9/site-packages/gym/envs/registration.py:619: UserWarning: WARN: Env check failed with the following message: The environment cannot be reset with a random seed. This behavior will be deprecated in the future.
You can set `disable_env_checker=True` to disable this check.
logger.warn(
We define the cost and constraint functions according to the problem description.
[4]:
# Tolerable probability of failure.
delta = 0.1
def _cost_fn(time: int = 0, state: np.ndarray = None) -> float:
"""CWH cost function.
The cost is defined such that we seek to minimize the distance from the system
to the origin. This would indicate a fully "docked" spacecraft with zero
terminal velocity.
"""
dist = state - np.array([0, 0, 0, 0], dtype=np.float32)
result = np.linalg.norm(dist, ord=2, axis=1)
result = np.power(result, 2)
return result
def _constraint_fn(time: int = 0, state: np.ndarray = None) -> float:
"""CWH constraint function.
The CWH constraint function is defined as the line of sight (LOS) cone from the
spacecraft, where the velocity components are sufficiently small.
Note:
The constraints are written in terms of indicator functions, which return a
one if the sample is in the LOS cone (or in the target space) and a zero if
it is not, but the optimal control problem is defined such that the
constraints are satisfied if the function is less than or equal to zero.
Thus, we use the following algebraic manipulation::
1[A](x) >= 1 - delta
- 1[A](x) <= -1 + delta
- 1[A](x) + 1 - delta <= 0
"""
# Terminal constraint.
if time < time_horizon - 1:
satisfies_constraints = (
-np.array(
(np.abs(state[:, 0]) < np.abs(state[:, 1]))
& (np.abs(state[:, 2]) <= 0.05)
& (np.abs(state[:, 3]) <= 0.05),
dtype=np.float32,
)
+ 1
- delta
)
return np.round(satisfies_constraints, decimals=2)
# LOS constraint.
else:
satisfies_constraints = (
-np.array(
(np.abs(state[:, 0]) < 0.2)
& (state[:, 1] >= -0.2)
& (state[:, 1] <= 0)
& (np.abs(state[:, 2]) <= 0.05)
& (np.abs(state[:, 3]) <= 0.05),
dtype=np.float32,
)
+ 1
- delta
)
return np.round(satisfies_constraints, decimals=2)
Algorithm#
Now, we can compute the policy using the algorithm, and then simulate the system forward in time using the computed policy.
[5]:
# Compute policy.
policy = KernelControlFwd(
time_horizon=time_horizon,
cost_fn=_cost_fn,
constraint_fn=_constraint_fn,
verbose=False,
kernel_fn=rbf_kernel,
regularization_param=regularization_param,
)
policy.train(S=S, A=A)
# Simulate the controlled system.
env.reset()
initial_condition = [-0.8, -0.8, 0, 0]
env.reset(initial_condition)
trajectory = [initial_condition]
for t in range(time_horizon):
action = policy(time=t, state=env.state)
state, *_ = env.step(time=t, action=action)
trajectory.append(list(state))
/home/docs/checkouts/readthedocs.org/user_builds/socks/envs/develop/lib/python3.9/site-packages/gym_socks/algorithms/control/common.py:169: DeprecationWarning: The 'warn' method is deprecated, use 'warning' instead
logger.warn("No feasible solution found!")
WARNING - gym_socks.algorithms.control.common - No feasible solution found!
Results#
We then plot the simulated trajectory of the system using the policy.
[6]:
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure()
ax = plt.axes()
# Plot the constraint shapes.
verts = [(-1, -1), (1, -1), (0, 0), (-1, -1)]
codes = [
matplotlib.path.Path.MOVETO,
matplotlib.path.Path.LINETO,
matplotlib.path.Path.LINETO,
matplotlib.path.Path.CLOSEPOLY,
]
path = matplotlib.path.Path(verts, codes)
plt.gca().add_patch(matplotlib.patches.PathPatch(path, fc="none", ec="blue"))
plt.gca().add_patch(plt.Rectangle((-0.2, -0.2), 0.4, 0.2, fc="none", ec="green"))
trajectory = np.array(trajectory, dtype=np.float32)
plt.plot(
trajectory[:, 0],
trajectory[:, 1],
color="C1",
marker="o",
label="System Trajectory",
)
plt.legend()
plt.show()
WARNING - matplotlib.font_manager - Matplotlib is building the font cache; this may take a moment.
INFO - matplotlib.font_manager - generated new fontManager